GOLD Parser 로 파싱하기
대부분의 파서 생성기는 코드 생성을 기반으로 동작한다. yacc, bison, antlr 모두 그러한 형태를 기본 방법으로 사용하고 있다. 이 방향은 최적화를 고려하거나 문법 정의와 동작 파일로 부터 바로 결과물을 보고 싶다면 괜찮은 방법이다. 하지만 이 방법은 다음과 같은 단점을 가지고 있다.
- 언어 문법 정의와 파싱 동작이 분리되어 있지 않아 다소 복잡하다.
- 언어 문법을 기술하기 위해 정규식, BNF 뿐 아니라 파서 생성기 고유의 사용법에 익숙해져야 한다.
- 코드 생성을 담당하는 파서 생성기에 빌드 종속이 생긴다.
이런 아쉬움을 pyparsing, boost::spirit 은 호스트 언어를 사용해서 문법을 정의하는 방식으로 풀었다. 때문에 문법 정의와 사용 부분이 언어가 동일하기 때문에 둘 사이의 껄끄러움이 덜하다. 하지만 특정 언어 환경에서만 사용할 수 있는 제약이 생기는 것은 어쩔 수 없는데 pyparsing 은 python 에서만 boost::spirit 은 C++ 에서만 사용할 수 있다. 만약 언어 파싱을 C++, Python 에서 동시에 사용해야 한다면 이는 문제가 된다.
이런 와중에 GOLD Parser 는 파싱하고자 하는 언어의 문법을 파싱할 수 있는 데이터를 익스포트 하고 이를 각자의 환경에서 사용하는 방식을 사용한다. 기본적인 파싱 데이터인 DFA 테이블과 LALR 테이블을 익스포트 하고 이후 파싱 작업은 각 언어 마다 개별적으로 구현한 파싱 엔진에 위임한다. 파싱 엔진은 여러 언어마다 개별 개발자들이 만들어 두었다.
언어 문법과 파싱에서의 사용을 분리했는데 나름 괜찮은 시도인 것 같아 사용해보았다. (이런 접근은 GOLD Parser 말고는 그다지 많이 사용되고 있지 않다. SableCC 가 부분적으로 이 기능을 지원한다.)
GOLD Parser IDE
골드 파서는 언어를 정의할 수 있도록 문법과 이 문법을 사용해 언어 문법을 작성할 수 있는 IDE 를 제공한다. 이 IDE 를 통해 파싱할 언어의 문법을 작성하는데 IDE 라서 Syntax Highlighting 부터 테스트 작성 및 (그래도 친절한) 문법 오류 안내를 지원한다. 보통의 파서 생성기는 이러한 도구가 없거나 부실해 그 환경에 익숙해지지 않으면 사용하기 어렵다.
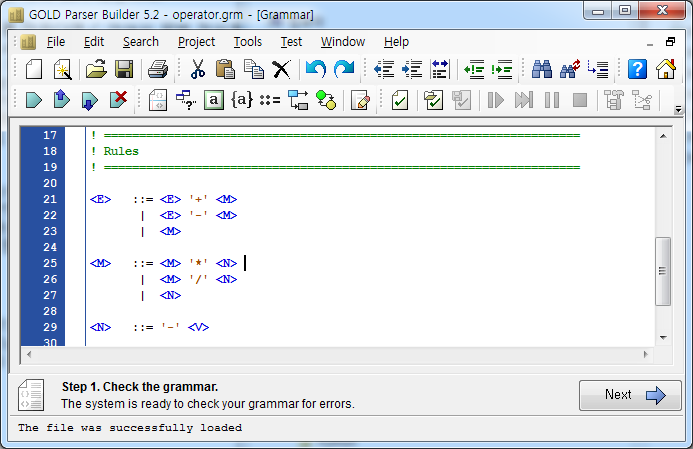
문법을 작성하면서 작성된 문법을 테스트 할 수 있다. 테스트 하고자 하는 문자열을 입력하고 이 문자열이 올바르게 파싱되는지 확인할 수 있다. 파싱 결과를 파싱 이벤트 혹은 파스 트리를 통해 확인해 볼 수 있다.
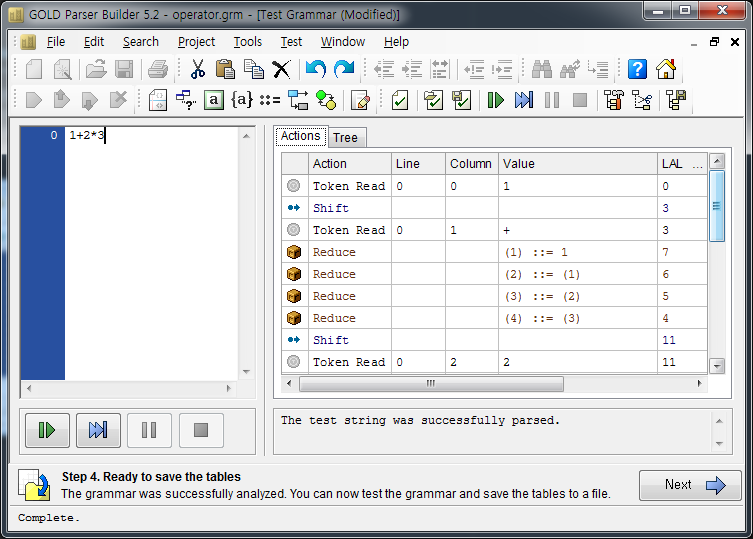
문법 만들기
골드 파서로 파싱할 언어의 문법을 작성해보자. 예를 위해 간단한 계산기 파서를 만들어 보자.
이 언어는 정수를 대상으로 +, -, *, / 를 처리할 수 있고 괄호를 인식한다.
이 언어는 아래와 같은 입력을 처리할 수 있다.
-(10+20+35)*4/20
골드 파서는 보통의 파서 생성기와 같이 토큰 정의에 정규식을 문법 정의이 DNF 를 사용한다.
먼저 계산기 토큰을 정의하자. 계산기를 이루는 가장 주요한 토큰은 숫자다.
0 을 포함한 양의 정수를 정의하자.
(음의 정수는 1항 연산자 - 로 처리한다.)
{Digi9} = {Digit} - ['0']
Num = '0' | {Digi9}{Digit}*
토큰을 정의했으면 토큰을 가지고 BNF 를 사용해 문법을 정의하자.
골드 파서는 단순한 토큰은 문법 정의 때 따로 정의 없이 바로 사용할 수 있다.
(+, - 등) 아래 문법은 우선순위를 고려한 애매함 없는 계산기 언어의 문법이다.
<E> ::= <E> '+' <M>
| <E> '-' <M>
| <M>
<M> ::= <M> '*' <N>
| <M> '/' <N>
| <N>
<N> ::= '-' <V>
| <V>
<V> ::= Num
| '(' <E> ')'
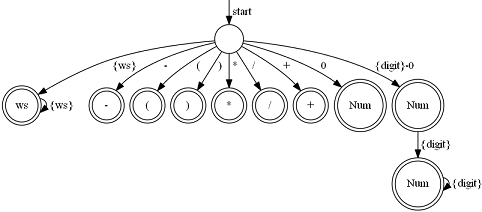
이렇게 토큰과 문법을 정의하고 나면 이 결과를 operator.egt 파일로 저장한다. 이 파일에는 언어 문법을 구성하는 토큰과 생성 규식이 들어있고 파싱에 중요한 역할을 하는 DFA 테이블과 LALR 테이블이 계산되어 포함된다. 위 계산기 토큰의 DFA 는 아래와 같은 형태를 가진다.
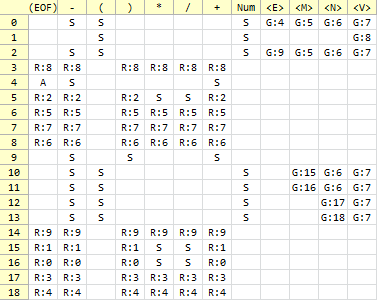
계산기 문법의 LALR 테이블은 아래와 같다. (S:Shift, R:Reduce, G:Goto, A:Accept)
자 이제 문법 데이터를 만들었으니 파싱을 해보자.
파싱
주어진 테이블로 어떻게 파싱하는지는 엔진 마다 다르다. 따라서 엔진은 동작하는 언어 뿐 아니라 문법 데이터를 사용하는 방식까지 결정한다. 여기서는 파이썬 엔진인 PyAuParser 를 사용하기로 하자. 라이브러리를 import 하고 문법 파일인 operator.egt 를 읽어 주어진 식을 파싱한다. 파싱 중간 결과를 그대로 출력하는 예는 다음과 같다.
g = pyauparser.Grammar.load_file("operator.egt")
def callback(ret, arg):
print "{0}\t{1}".format(ret, arg)
pyauparser.parse_string(g, "-(10+20+35)*4/20", handler=callback)
이를 실행하면 다음과 같이 LALR 파싱 결과가 출력되는 것을 볼 수 있다.
SHIFT S=1, T=- '-'
SHIFT S=2, T=( '('
SHIFT S=3, T=Num '10'
REDUCE P=8, H=(S=7, P=<V> ::= Num), Hs=[(S=3, T=Num '10')]
REDUCE P=7, H=(S=6, P=<N> ::= <V>), Hs=[(S=7, P=<V> ::= Num)]
REDUCE P=5, H=(S=5, P=<M> ::= <N>), Hs=[(S=6, P=<N> ::= <V>)]
REDUCE P=2, H=(S=9, P=<E> ::= <M>), Hs=[(S=5, P=<M> ::= <N>)]
...
LALR 는 상향식 파서이기 때문에 Reduce 이벤트가 파스 트리 (Parse Tree) 의 말단에서 루트 방향으로 발생한다. -(10+20 까지 파싱되었을 때의 파스 트리를 구축하면 아래와 같다. #번호로 표시된 것이 Reduce 이벤트 발생 순서다. 만약 이러한 post-order 트리 탐색이 충분하다면 이 이벤트를 잡아서 처리할 수 있다.
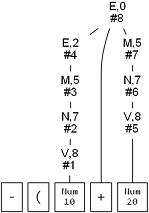
계산기는 이 순서로 충분히 계산해 낼 수 있으므로 아래와 같이 실제 계산을 하는 핸들러를 넣어 계산기를 구현할 수 있다.
h = pyauparser.ProductionHandler({
'<E> ::= <E> + <M>': lambda c: c[0] + c[2],
'<E> ::= <E> - <M>': lambda c: c[0] - c[2],
'<E> ::= <M>': lambda c: c[0],
'<M> ::= <M> * <N>': lambda c: c[0] * c[2],
'<M> ::= <M> / <N>': lambda c: c[0] / c[2],
'<M> ::= <N>': lambda c: c[0],
'<N> ::= - <V>': lambda c: -c[1],
'<N> ::= <V>': lambda c: c[0],
'<V> ::= Num': lambda c: int(c[0].lexeme),
'<V> ::= ( <E> )': lambda c: c[1],
}, g)
pyauparser.parse_string(g, "-(10+20+35)*4/20", handler=h)
print "Result = {0}".format(h.result)
이벤트를 사용하는 것은 파스 트리를 구축하는 비용이 없어 좋다. 하지만 XML 의 DOM 과 같이 파싱 결과를 담고 있는 트리를 가지고 작업을 하는 것이 좀 더 편하고 강력하다. (만약 입력식 최적화를 염두하고 있다면 이 방법을 사용해야 한다.) 계산식을 파싱해 파스 트리를 구성하자.
tree = pyauparser.parse_string_to_tree(g, "-(10+20+35)*4/20")
이 계산식은 아래와 같은 파스 트리를 만들어 낸다. 파스 트리를 보면 어떻게 계산을 하면 좋을지 상상 할 수 있다. :)
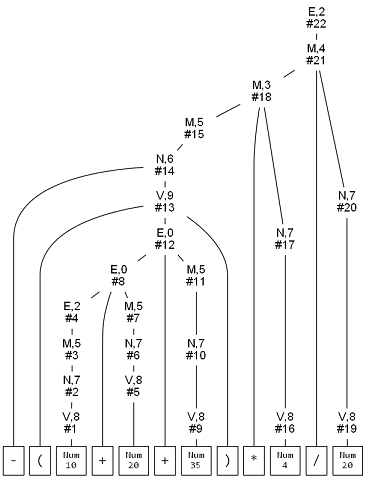
아래와 같이 구축된 트리를 순회하면서 결과를 계산할 수 있다.
def evaluate(node):
r = lambda s: g.get_production(s).index
h = {
r('<E> ::= <E> + <M>'): lambda c: e(c[0]) + e(c[2]),
r('<E> ::= <E> - <M>'): lambda c: e(c[0]) - e(c[2]),
r('<E> ::= <M>'): lambda c: e(c[0]),
r('<M> ::= <M> * <N>'): lambda c: e(c[0]) * e(c[2]),
r('<M> ::= <M> / <N>'): lambda c: e(c[0]) / e(c[2]),
r('<M> ::= <N>'): lambda c: e(c[0]),
r('<N> ::= - <V>'): lambda c: -e(c[1]),
r('<N> ::= <V>'): lambda c: e(c[0]),
r('<V> ::= Num'): lambda c: int(c[0].lexeme),
r('<V> ::= ( <E> )'): lambda c: e(c[1]),
}
def e(node):
handler = h[node.production.index]
return handler(node.childs)
return e(node)
result = evaluate(tree)
print "Result = {0}".format(result)
이 파스 트리로도 계산은 충분히 가능하지만 복잡한 문법의 입력을 처리할 때는 불필요한 노드와 토큰을 제거한 추상 구문 트리 (Abstract Syntax Tree) 를 구축하는 것이 유리하다. PyAuParser 의 SimplifiedTree 기능으로 아래와 같이 AST 를 만들 수 있다.
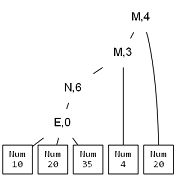
파싱에는 필요하지만 실제 계산에는 필요하지 않은 토큰이 제거되었고 (+, -, …)
불필요한 노드도 제거되었다.
뿐만 아니라 10 + 20 + 35 을 구성하는 노드가 리스트 형태로 펼쳐진 것을 볼 수 있다.
결론
골드 파서는 DFA, LALR 를 사용하기 때문에 표현력이 좋다. 따라서 웬만한 언어는 파싱 가능하다. 또한 문법과 엔진을 분리해서 원하는 환경의 엔진을 구할 수 있다면 1개의 문법 파일로 여러 환경에서 파싱을 할 수 있다.
다만 한계가 있는데
-
DFA, LALR 을 벗어나는 언어 처리가 어렵거나 혹은 불가능하다.
사실 대부분의 인기있는 프로그래밍 언어는 문맥 자유 문법에서 벗어난다. 예를 들어 ANSI-C 나 Python 만 해도 이 틀에서 벗아나는데 이를 처리하기 위해 보통의 파서 생성기는 우회 처리 방법을 지원한다. 하지만 골드 파서는 그럴 수가 없다. (애초에 언어의 문법과 처리를 분리했기 때문에)
-
엔진의 공통 API 가 없다.
레퍼런스로 제공되는 VB.NET 파서 엔진이 제공되긴 하나 이를 강제하지 않고 있다. 따라서 각 언어 환경의 엔진을 만드는 개발자 마다 다른 API 구성이 조금씩 다르다. 때문에 여러 언어를 동시에 지원할 때는 코드 작업이 늘어날 수 있다. 하지만 DFA, LALR 을 사용하는 점은 다르지 않아 Reduce 이벤트에 의존하는 구성은 동일하기 때문에 크게 문제가 되지는 않는다. 하지만 파스 트리 구축이나 AST 변환은 지원 여부부터 사용 방법까지 모두 다르기 때문에 여러 언어 환경에서 일관성 있는 사용은 사실상 어렵다.
하지만 사용하기 좋은 IDE 를 지원하고 기본 기능에만 집중했기 때문에 나름대로 (!) 사용해볼만 하다. (위에서 예로든 PyAuParser 도 골드 파서를 가지고 놀다가 만든 직접 만들어 본 엔진이다.)